
Open WebUI
Open WebUI est une interface web de conversation IA.
User-friendly WebUI for LLMs (Formerly Ollama WebUI)
Dépôt GitHub : https://github.com/open-webui/open-webui
Documentation : https://docs.openwebui.com
Journaux liées à cette note :
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?
Dans une note de juillet 2025, j'évoquais ne pas avoir trouvé d'information sur les limites de consommation de tokens de l'offre "Pro" de Claude.
J'avais observé empiriquement qu'avec mon usage de Claude Sonnet à l'époque, l'API directe était plus avantageuse qu'un abonnement Pro :
Entre le 30 mai et le 15 juillet 2025, j'ai consommé
$14,94de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
En 2026, avec la forte augmentation de l'usage des AI code assistant de type Claude Code ou OpenCode, la consommation de tokens a explosé, ce qui change la donne.
Je me pose à nouveau la question suivante : « Est-ce que les abonnements sont maintenant réellement plus économiques que l'utilisation directe de l'API ? ».
Cette semaine, j'ai effectué de nouvelles recherches pour en savoir plus sur les limites des abonnements Claude et cette fois, j'ai trouvé dans ce thread Reddit des informations.
Dans cette article, l'auteur explique les résultats qu'il a trouvé par reverse engineering.
Attention, l'unité "credits" est différente de "tokens". La définition de crédit est donné un peu plus loin dans cette note.
Le plan 20× n'est pas aussi avantageux qu'on pourrait le croire. Sur le site d'Anthropic, toutes les mentions « 20× plus d'utilisation* » comportent cet astérisque gênant. Les limites de session de cinq heures sont bien 20× plus élevées qu'en Pro, mais la vraie question est : quelle quantité de travail peut-on en tirer ? La réponse est : seulement deux fois plus par semaine que le plan 5×.
En revanche, le plan 5× offre un excellent rapport qualité-prix. Il tient largement ses promesses. C'est le point idéal du tableau tarifaire. Vous obtenez une limite de session six fois plus élevée que Pro (et non cinq), et plus de huit fois la limite hebdomadaire (davantage que l'éponyme cinq).
Tier Credits/5h Credits/week Pro 550,000 (1×) 5,000,000 (1×) Max 5× 3,300,000 (6×) 41,666,700 (8.33×) Max 20× 11,000,000 (20×) 83,333,300 (16.67×) Comparés aux tarifs de l'API, tous les abonnements semblent fantastiques. Les estimations de valeur dans le tableau sont des bornes inférieures, car la mise en cache rend l'équivalent API effectif encore plus favorable (je l'expliquerai dans un moment). Dans tous les cas, si vous pouvez utiliser un abonnement plutôt que l'API, foncez.
Tier Price Credits/month Opus-rate tokens Equivalent API cost Pro $20 21.7M 32.5M in or 6.5M out $163 (8.1×) Max 5× $100 180.6M 270.9M in or 54.2M out $1,354 (13.5×) Max 20× $200 361.1M 541.7M in or 108.3M out $2,708 (13.5×)
Voici un autre avantage de l'abonnement versus l'API :
Les lectures de cache. Elles sont entièrement gratuites.
Cela rend la balance encore plus favorable aux abonnements. Dans une boucle agentique (par exemple Claude Code), le modèle effectue des dizaines d'appels d'outils par tour. Après chaque appel d'outil, le modèle est invoqué à nouveau. Lecture du cache sur l'intégralité du contexte. L'API facture 10% pour chaque lecture ; les abonnements ne facturent rien. Ça s'accumule vite, comme nous allons le voir dans un instant.
Les écritures de cache sont également moins chères : elles coûtent 1,25×/2× le prix d'entrée sur l'API, tandis que sur l'abonnement elles sont facturées au prix d'entrée normal. Chaque tour de conversation est écrit dans le cache avant de pouvoir être lu, ce qui a donc aussi son importance.
Voici le lien entre credit et tokens :
Ce sont les unités utilisées en interne pour suivre la consommation de votre abonnement. « Crédits » est mon nom arbitraire pour ça — ces valeurs n'apparaissent pas directement dans un champ de l'API, donc il n'y a pas de mot évident pour les désigner. Je trouve que « crédits » sonne bien.
Comment passe-t-on des crédits aux tokens ? Voici la formule :
credits_used = ceil(input_tokens × input_rate + output_tokens × output_rate)...et les valeurs à y insérer :
Modèle Crédits/token en entrée Crédits/token en sortie Haiku 2/15 = 0,133... 10/15 = 2/3 = 0,666... Sonnet 6/15 = 2/5 = 0,4 30/15 = 2 Opus 10/15 = 2/3 = 0,666... 50/15 = 10/3 = 3,333... Les valeurs spécifiques semblent assez arbitraires, mais les ratios entre elles reflètent la tarification de l'API : la sortie coûte 5× l'entrée, vous paierez 5× plus pour Opus que pour Haiku, etc.
Après la lecture de cet article, il est clair que je vais utiliser principalement un abonnement Claude plutôt que des tokens d'API. Cependant, l'accès à un LLM par abonnement est moins flexible qu'une OpenAI Chat Completions compatible API.
Par exemple, je ne peux pas connecter Open WebUI, LibreChat ou toute autre application qui nécessite un accès direct à un LLM.
Mi-janvier 2026, j'ai lu ce thread à propos d'un "hack" utilisé par OpenCode pour accéder directement à l'API Anthropic avec un abonnement Claude. Ça m'a donné l'idée de chercher des outils de type "proxy" capables d'exposer une OpenAI Chat Completions compatible API à partir d'un abonnement Claude.
En fouillant sur Reddit, dans ce thread, j'ai trouvé les projets suivants :
Je compte tester ces deux projets dans les semaines à venir.
Journal du mercredi 24 décembre 2025 à 14:59
Un ami vient de me poser cette question :
tu es content de Mammouth ? ça s'intègre bien à Zed, VSCode ?
Il fait probablement référence à ma note du 2025-11-16_1325.
Comme je l'indiquais à l'époque :
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
Finalement, je n'ai pas utilisé Mammouth et je suis resté sur le couple Open WebUI et OpenRouter.
Par ailleurs, je n'ai jamais essayé Zed editor et je n'utilise plus VS Code depuis mi-2022 (voir Historique des éditeurs texte que j'ai utilisés).
Voici ce que j'utilise depuis début 2025 pour les LLM :
Au quotidien, j'utilise Open WebUI connecté à OpenRouter pour accéder à différents modèles LLM (voir Quelle est mon utilisation d'OpenRouter.ia ?).
Pour les AI code assistant, j'ai d'abord utilisé avante.nvim, puis depuis quelques mois j'utilise principalement Aider.
Par exemple, j'ai implémenté 90% du projet qemu-compose avec Aider (voir section Development approach).
J'utilise aussi llm (cli), mais sans doute pas encore assez.
Ce que j'envisage de tester :
- AIChat pour remplacer llm (cli) et potentiellement Open WebUI
- Claude Code pour le comparer à Aider
- Avante Zen Mode pour éventuellement remplacer Aider
- LibreChat pour potentiellement remplacer Open WebUI
Avec AIChat et LibreChat, je souhaite commencer à utiliser sérieusement les tools (LLM) et des services MCP.
Ce que je compte conserver : OpenRouter.
Journal du dimanche 16 novembre 2025 à 13:25
Dans la vidéo de Monsieur Phi "L'autonomie des IA expliquée aux humains", #JaiDécouvert le service Mammouth, qui me rappelle un peu OpenRouter.
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
L'objectif produit de Mammouth ressemble pas mal au projet Albert Conversation sur lequel j'ai travaillé à la DINUM entre avril et août 2025.
Journal du jeudi 17 juillet 2025 à 15:44
Voici comment perdre presque deux heures bêtement !
#!/usr/bin/env python3
import requests
import os
session = requests.Session()
session.headers.update({"Content-Type": "application/json"})
auth_response = session.post(
"http://localhost:3000/api/v1/auths/signin",
json={
"email": "contact+admin@stephane-klein.info",
"password": os.environ['OPEN_WEBUI_ADMIN_PASSWORD']
}
)
session.headers.update({
"Authorization": f'Bearer {auth_response.json()["token"]}'
})
with open("hello_world.py", "r") as f:
response = session.post(
"http://localhost:3000/api/v1/pipelines/upload",
files={
"file": ("hello_world3.py", f, "text/x-python")
},
data={
"urlIdx": "2"
}
)
print(response.text)
L'API de Open WebUI envoyait cette erreur :
{"detail":[{"type":"missing","loc":["body","urlIdx"],"msg":"Field required","input":null},{"type":"missing","loc":["body","file"],"msg":"Field required","input":null}]}
Mon erreur se situé au niveau de la ligne :
session.headers.update({"Content-Type": "application/json"})
Si je supprime cette ligne, le script fonctionne parfaitement.
Il semble que la fonction session.post() ne configure pas correctement le Content-Type multipart lorsque ce header a été défini au préalable au niveau de la session.
J'ai cherché pendant quelques minutes une issue à ce sujet, sans succès.
Dans l'idéal, requests devrait émettre un warning dans cette situation.
Je viens de créer cette issue : "POST Multipart-Encoding does not work if the Content-Type header has been previously defined in the session"
#UnJourPeuxÊtre je proposerai aussi une implémentation.
D'autre part, ma configuration :
session.headers.update({"Content-Type": "application/json"})
n'avait aucune utilité puisque post définit automatiquement "Content-Type": "application/json" quand on utilise le paramètre json= 🙈.
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ai.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
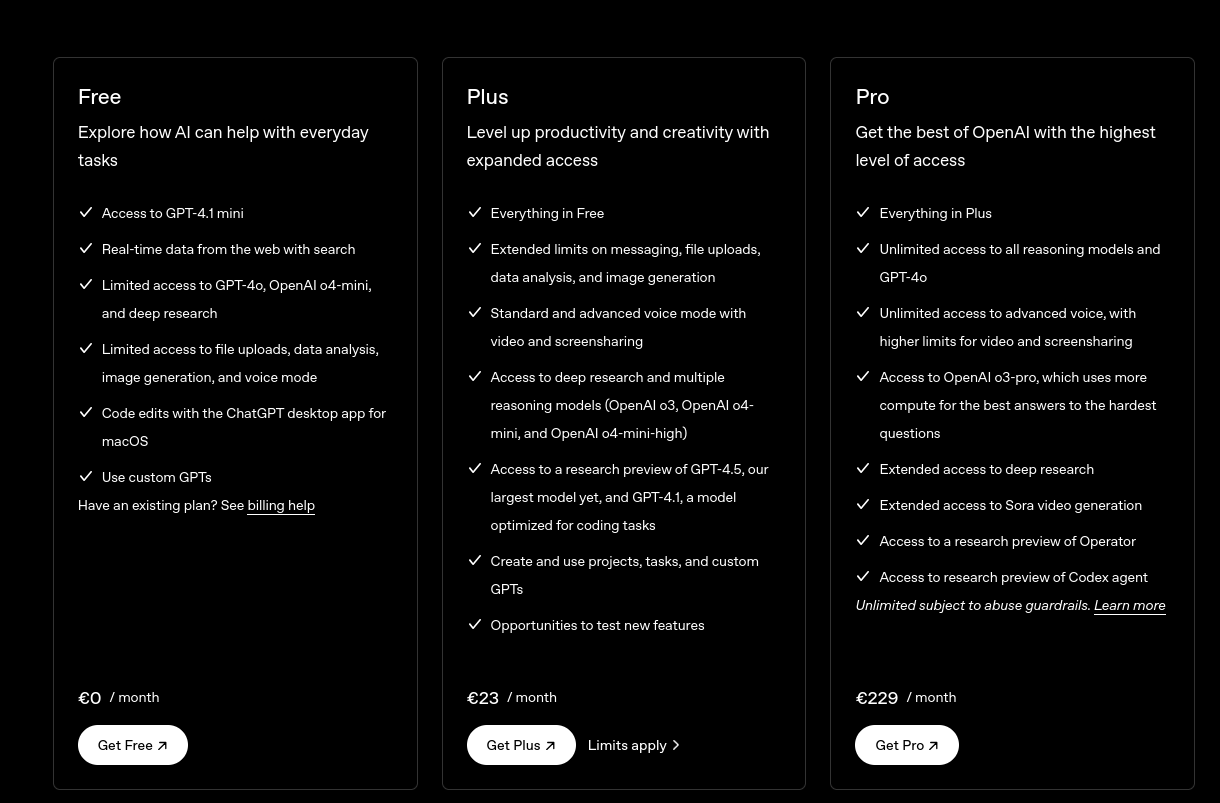
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
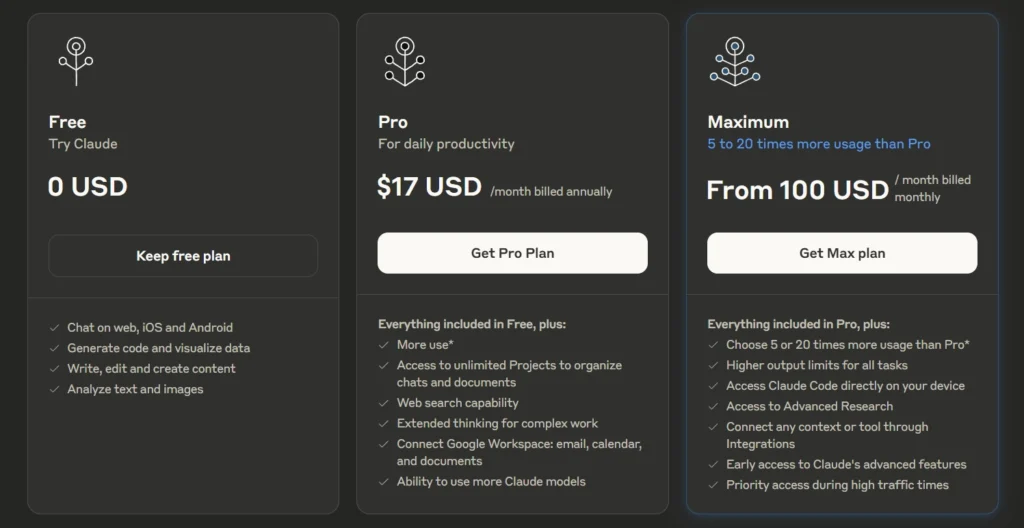
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
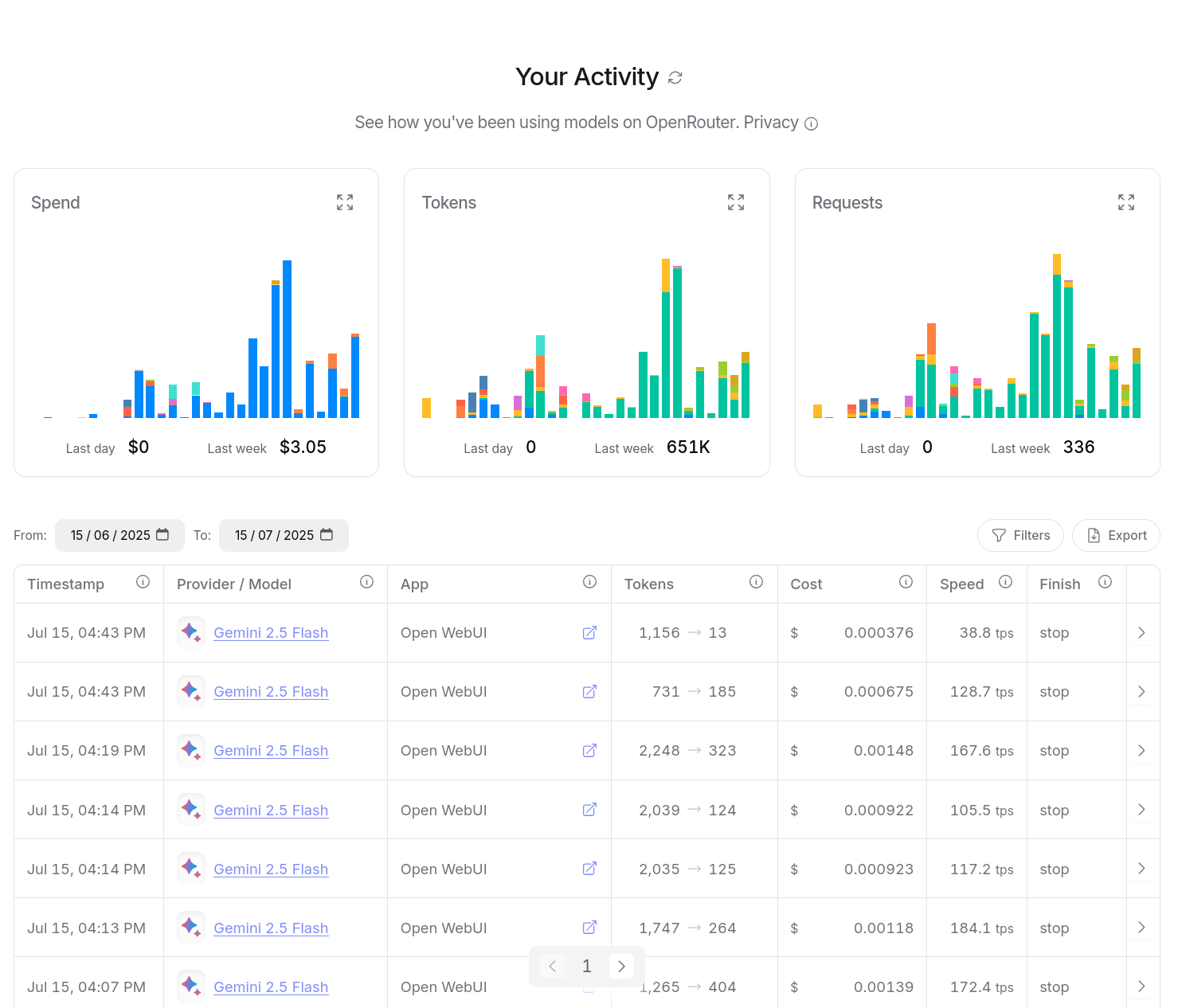
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
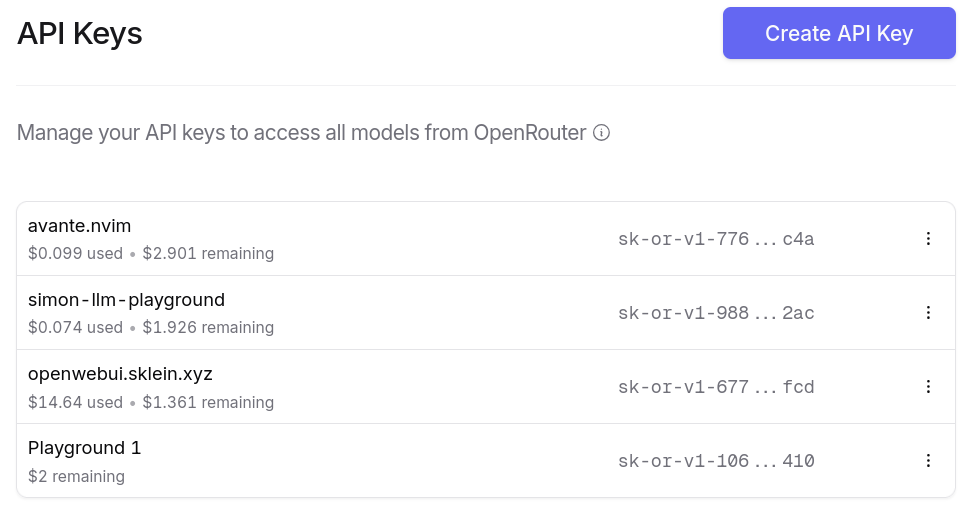
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Est-ce qu'une fonction Open WebUI peut importer une autre fonction Open WebUI ?
J'ai essayé de comprendre si une fonction Open WebUI pouvait importer le code d'une autre fonction Open WebUI.
La réponse est non. Je vais tenter dans cette note d'expliquer pourquoi.
(j'ai aussi publié une version de cette note en anglais dans la section "discussions" de Open WebUI)
Open WebUI propose de méthode pour créer ou mettre à jour une fonction Open WebUI sur une instance en production : via l'interface web d'administration, ou via l'API REST.
Une instance production fait référence à Open WebUI hébergé sur une Virtual machine ou un Cluster Kubernetes, par opposition à une instance locale lancée en mode développement.
Dans un premier temps, j'ai essayé d'importer dans Open WebUI les deux fichiers suivants :
# utils.py
def add(a, b):
return a + b
# hello_world.py
from pydantic import BaseModel, Field
from .utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le fichier hello_world.py contient un import de utils.add implémenté dans le premier fichier.
L'importation du premier fichier est refusée par Open WebUI parce que class Pipe: est absent de utils.py.
J'ai ensuite trompé Open WebUI en ajoutant une classe Pipe fictive das le fichier utils.py et l'importation a réussi.
Ensuite l'import de hello_world.py a échoué parce que Open WebUI n'arrive pas a effectué l'import from .utils import add. J'ai ensuite effectué plusieurs tentatives d'import absolut, par exemple from open_webui.utils import add… mais sans succès.
J'ai pris un peu de temps pour étudier l'implémentation d'Open WebUI et j'ai identifié cette section de code :
module_name = f"tool_{tool_id}"
module = types.ModuleType(module_name)
sys.modules[module_name] = module
Ce code permet à Open WebUI de charger dynamiquement le code source des modules qui sont stockés dans la base de données.
Un esprit tordu pourrait en pratique importer une fonction chargé dynamiquement dans un autre module dynamique, par exemple :
from tool_utils import add
Mais cette méthode ne correspond pas à l'usage normal d'Open WebUI.
Pour implémenter des fonctions "modulaires", Open WebUI conseille d'utiliser la fonctionnalité "Pipelines" :
Welcome to Pipelines, an Open WebUI initiative. Pipelines bring modular, customizable workflows to any UI client supporting OpenAI API specs – and much more! Easily extend functionalities, integrate unique logic, and create dynamic workflows with just a few lines of code.
Pour les personnes qui souhaitent vraiment effectuer des imports dans des fonctions Open WebUI sans utiliser la fonction Pipelines, il existe tout de même une solution que j'ai implémentée dans la branche test-if-openwebui-function-support-import.
Voici le contenu de /functions/hello_world.py :
from pydantic import BaseModel, Field
from open_webui.shared.utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le contenu de /shared/utils.py
def add(a, b):
return a + b
Pour rendre accessible /shared/utils.py dans l'instance d'Open WebUI lancé loculement, j'ai configuré de volume mounts suivante dans mon /docker-compose.yml :
openwebui:
image: ghcr.io/open-webui/open-webui:0.6.15
restart: unless-stopped
volumes:
- ./shared/:/app/backend/open_webui/shared/
ports:
- "3000:8080"
Ensuite, si je souhaite pouvoir déployer en production cette fonction Open WebUI et le module utils.py, il sera nécessaire de build une image Docker customisé d'Open WebUI pour y inclure le fichier /shared/utils.py.
Cette méthode peut fonctionner, mais cela reste un "hack" non conseillé. Il est préférable d'utiliser la méthode "Pipelines".
Aggregator - Backup Numeric Conversation System
Ce matin, j'ai eu l' #idée et l’envie de créer une appli d'archivage et de centralisation de toutes mes conversations numériques.
L'objectif ? Rassembler en un seul endroit, dans une interface web minimaliste, toutes mes discussions provenant de :
- ChatGPT
- Claude.ai
- Open WebUI
- Mes threads Mattermost
- Mes Mail
Le support des threads serait utile pour Mattermost et les mails. J'aimerais pouvoir sauvegarder tous ces messages au format brut original et en Markdown. Une fonction pour partager un message ou un thread serait aussi sympa.
Pour la persistance des données, je pense utiliser ElasticSearch avec son moteur vectoriel. Un LLM pourrait assigner automatiquement des tags à chaque conversation. J'aimerais que l'interface web soit minimaliste, orientée vitesse et exploration.
Pour la postérité, toutes ces données devraient être exportées en continu dans un Object Storage, sous un format YAML facilement compréhensible.
Je me demande si ce type d’application existe en Open source ou closed-source 🤔.
Journal du samedi 14 juin 2025 à 00:06
#JaiDécouvert OmniPoly (https://github.com/kWeglinski/OmniPoly)
Welcome to a solution for translation and language enhancement tool. This project integrates LibreTranslate for accurate translations, LanguageTool for grammar and style checks, and AI Translation for modern touch of sentiment analysis and interesting sentences extraction.
Je souhaite intégrer cet outil au dépôt sklein-open-webui-instance.
Comme ce projet ne sera plus exclusivement dédié à Open WebUI, il me semble qu'un changement de nom s'impose.